Deep Learning(DL)を用いたテーブルデータ向けの手法は色々提案されており、度々、精度面で勾配ブースティング法を超えたとか超えないと話題になる気がします。
テーブルデータ周りのDL手法に詳しくない身からすると実際のところどうなのかというのは謎だったので、サーベイ論文を読んでみました。
読んだ論文:Deep Neural Networks and Tabular Data: A Survey
手法の細かい説明をまとめるのはしんどいので省略して、結果の部分だけのメモになります。
評価値での比較
下図は各手法のデータセットごとの評価値の比較結果をあらわしています。上部は非DL手法で、下部DL手法になります。

これをみると、だいたいのデータセットに対してDL手法よりもXGBoostやLightGBM、CatBoostといった勾配ブースティング法が勝っていることがわかります。ただし、HIGGSデータセットではDL手法であるSAINTが他手法に勝っています。
HIGGSデータセットはシミュレーションによって作成されたデータセットであり、データ数は1100万という巨大なものになります。巨大なデータセットに限ってはDeep Learning手法が有利になるのかもしれません。
Accuracyと計算時間比較
次にAccuracyと計算時間(訓練と推論)の比較になります。DL手法と勾配ブースティングはGPU利用のようです。
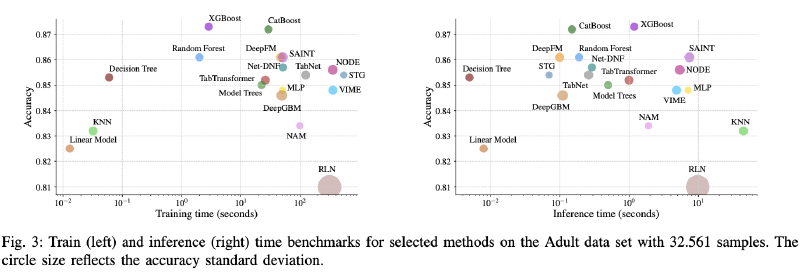
Adultデータセット
下図はAdultデータセットの場合をあわらしています。図中で左上にある手法ほど良く、右下に近いほど良くない手法という見方になります。

これをみると、訓練と推論の両方で左上に書かれている決定木はバランスが良いです。
Accuracyを優先するならXGBoostやCatBoostといった選択肢があるという結果になっています(LightGBMはどこにいったのか?)。
DL手法で比較的良いのはDeepFMといえるでしょうか。
HIGGSデータセット
下図はHIGGSデータセットの場合をあらわしています。
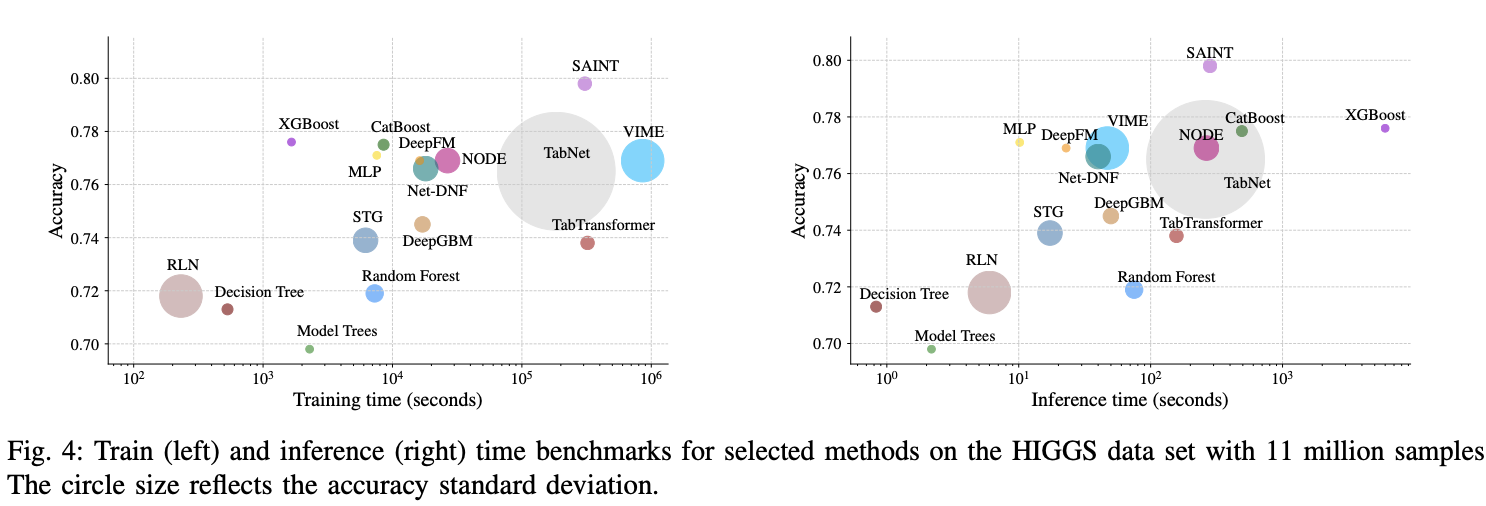
訓練はXGBoostやCatBoostが良いのですが、推論に比較的時間がかかるという結果になっています。このデータセットに対しては深い木になっているのかもしれません。
主観ですが、訓練と推論の両方でバランスが取れているのはMLP、DeepFMでしょうか?
Accuracyを求めるならSAINTですが、他手法よりも計算時間が多めです。
Accuracyとモデルサイズ比較
Adultデータセットの場合のDeep LearningモデルのモデルサイズとAccuracyの比較になります。
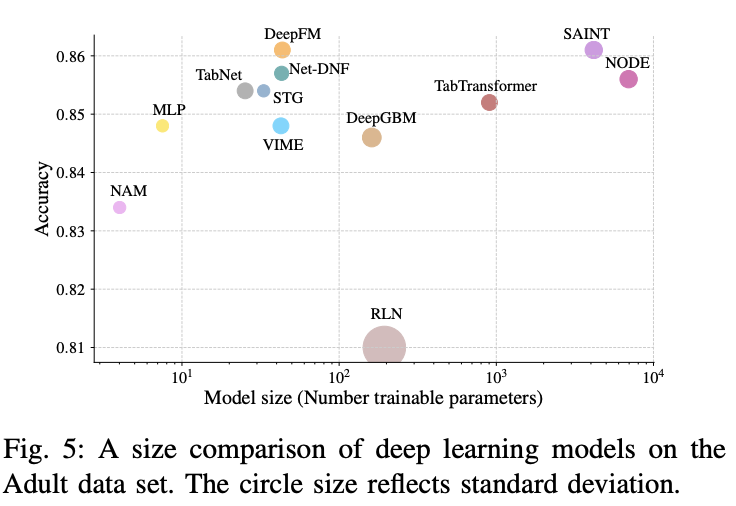
結果をみると、MLP、TabNet、DeepFMあたりが良いバランスでしょうか。
ここでもSAINTはAccuracyが高めですが、同程度のAccuracyのDeepFMと比べるとモデルサイズが2桁近く大きくなっています。実運用上はモデルサイズは非常に大事でクラウドで動かすときには料金に直結しうるため、場合によっては使用するのが難しいかもしれません。
ディープラーニングモデルの特徴量の分析
Ablation Test
次にディープラーニング手法のAttentionから得られる特徴量の寄与についての分析結果になります。
下記の上部の図(a)は寄与が大きい特徴量から順に削除・モデルを学習・評価というプロセスを繰り返したときのAccuracyの推移をあらわしています。
逆に下部の図(b)は寄与が小さい特徴量から順に削除していったケースをあらわします。
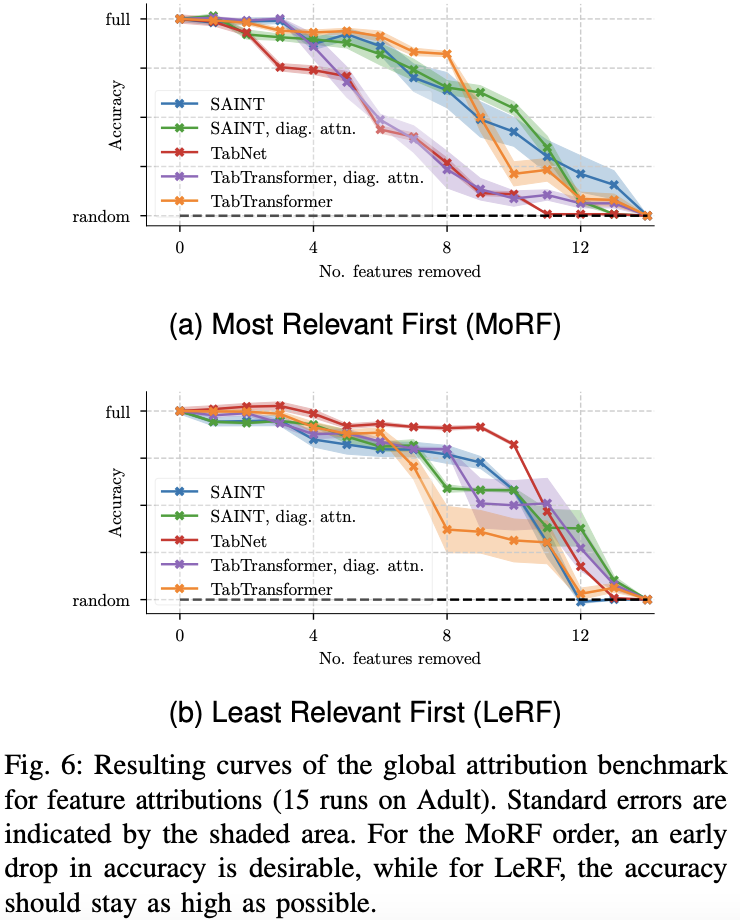
(a)の場合には寄与が大きい特徴量を順に削除していくため、本当に寄与が高ければすぐにAccuracyが落ちるはずです。
実際にはすぐにガクッとAccuracyが落ちていくことはなく、いくつか特徴量を削除してからようやくAccuracyが下がっていきます。
図中の手法のなかでは比較的TabNetのAccuracyがはやく落ちています。
(b)の場合には寄与が小さい特徴量を順に削除していくため、あまりAccuracyが落ちていかないことが予想されます。 ここでもTabNetが他手法よりも想定に近い挙動をしています。
以上から、比較的TabNetの寄与は信頼できるといえそうですが、全体的にはあまり予想通りの挙動ではないという印象です。
SHAPとの相関
最後にDL手法から求まった特徴量の寄与とSHAP値(SHAPから求まった特徴量の寄与)との相関になります。 SHAPは理論的にきちんとしている数少ない(唯一?)寄与の求め方になります。
もしDL手法から求まった特徴量の寄与が良いものであれば、SHAP値との相関が高くなることが予想されます。
2つの値はスケールが異なる都合、相関の計算にはスピアマンの順位相関係数を用いています。これは-1から1の範囲の値を取り、1は特徴量を寄与が高い順に並べた結果が全く同じ、-1は逆順、0は全く似ていないという結果をあらわします。

上の表をみると、ほとんど値が0ですので、DL手法で求まる寄与とSHAP値にはほぼほぼ相関がないということがわかります。
SHAP値の計算には時間が結構かかりますので、DL手法から求まる寄与がSHAP値に類似すると大変好都合なのですが、そうはならず残念です。
個人的な結論
ここまでの話を踏まえた上で、以下の理由からテーブルデータに対しては基本は決定木系の手法を使ってみるでOKという結論です。
- 高いAccuracy
- 訓練、推論の両方が比較的速い
- GPUが必須ではない
- SHAP値が厳密に高速に求まる
ただし、データが非常に大きかったり、マルチモーダルなデータ、テーブルデータのaugmentation、またコンペでのスタッキングなどのアンサンブル(実運用でやるのは稀かと思いますが)では活用されると思います。